Role: Designer / Engineer (solo)
Type: Personal project — designed, built, and shipped end-to-end
Stack: Next.js 16, TypeScript, SQLite via node:sqlite, Server-Sent Events, Tiptap, Radix UI
One designer, end to end: a product built around a single thesis — keep the hierarchy as the mental model — and engineered myself down to the client-side visibility function that makes it work.
The premise
Seeing everything makes it feel like I need to do everything.
Most task managers have the same answer to overload: filters and views. Hide what doesn't match your current context. The problem with that answer is that the hierarchy — which is usually the most important piece of information about a task — gets flattened into a list. You can no longer see how things relate.
Taskr is built around a different answer. The hierarchy is the primary mental model. Overload is solved by selectively hiding entire branches — snoozing a subtree until a date, or indefinitely — and then surfacing the right context through tags, due dates, and assignment views.
The product question I wanted to test: can a task manager preserve hierarchy and reduce cognitive load, simultaneously?
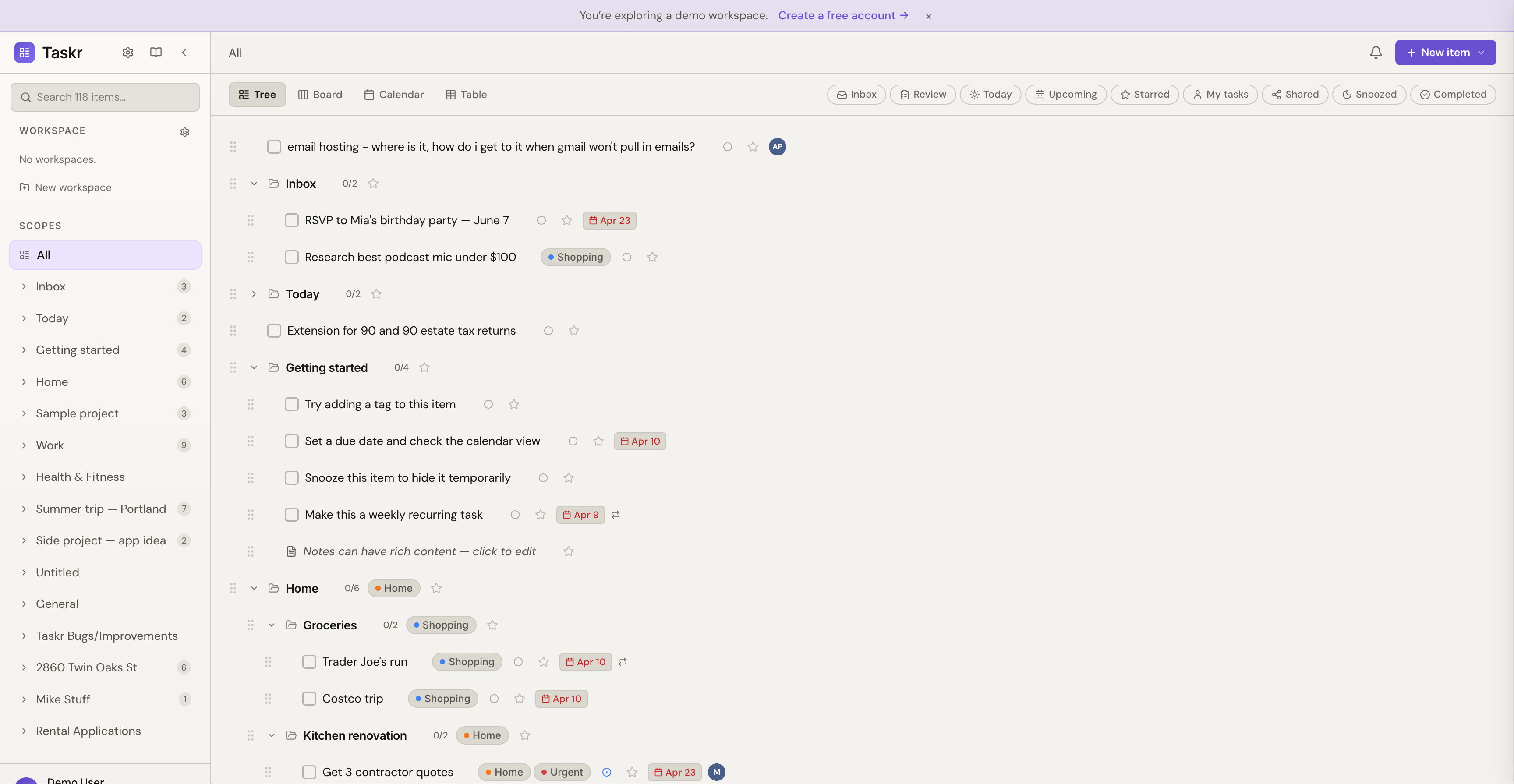
Core capabilities
- Snoozing. Hide a node and its entire subtree until a date or indefinitely. Resurface automatically. This is the central interaction — the thing the rest of the system is built around.
- Tag-based contextual filtering. Filter by tag, but with a twist: when you filter, you don't see a flat list of matching tasks. You see the full path from root → container → task. The tree explorer stays a tree explorer.
- Due dates & recurrence. Optional, with quick-set buttons (today, tomorrow, next week) and visual urgency chips. Daily, weekly, monthly, yearly schedules that roll forward on completion.
- Workspaces. Separate spaces for different contexts with role-based collaboration (owner / admin / member).
- Real-time sync. Server-Sent Events broadcast mutations across clients. Every change is felt by everyone connected, immediately.
- Magic-link auth. Passwordless email login. One less form to fight.
- Light & dark themes. System-aware with manual toggle.
The visibility engine
The core of the product is a single pure function — evaluateVisibility() — that takes the full tree and returns what should be shown. It runs entirely client-side, fully testable, no DB calls. The evaluation order:
- Snooze filter — build set of currently-snoozed node IDs
- Snooze propagation — any node whose
pathcontains a snoozed ancestor is also hidden - Tag filter — find direct tag matches, then expand to ancestors to preserve hierarchy
- Assignment filter — same pattern as tag filter, but matches on user assignments
- Snoozed view — shows directly-snoozed nodes plus their ancestors (context-preserving)
The single design insight that made the product feel right: ancestor expansion. When you filter by a tag, you don't just see matching tasks — you see them in their tree context. The interaction model never breaks.
Tree storage decisions
Nodes use an adjacency list (parent_id) combined with materialized paths (path = "ancestor1/ancestor2/.../self"). Adjacency list for simple parent/child CRUD; materialized path for O(n) subtree queries without recursion and O(1) ancestor lookup. The trade-off: paths must be updated on reparenting, but reparenting is rare relative to reads. Worth it.
What I'd take from this project
A clear thesis from the start makes a thousand small decisions easier. Every interaction in Taskr — snoozing, filtering, drag-and-drop reparenting — answers the same question: how do we preserve hierarchy as the user's mental model? When the answer to that question is consistent, the product feels coherent. When it isn't, no amount of polish on individual screens fixes the underlying confusion.
The other thing this project proved to me: the gap between "designer who specs" and "designer who ships" is closeable. Building the product I designed surfaced design problems I would not have noticed in a spec.